
Aerospike Graph, a real-time database, adds multi-model support.
Aerospike began offering a NoSQL database for advertising in 2009. Aerospike is now a real-time database platform for adtech, financial services, and consumer data platforms.
The firm began supplying a multi-model database in 2022, supporting the JSON document model, which has grown popular due to the success of document database provider MongoDB.
Aerospike Graph, a graph data model, is now available.
Graph databases help users comprehend links between data elements and information. Neo4J and Amazon Neptune are graph databases. Oracle’s graph database.
Graph databases are useful for numerous uses, including fraud detection, which Aerospike clients are increasingly using and needing a solution for.
Aerospike CEO Subbu Iyer told VentureBeat that last year they chose to construct a multi-model, multicloud data platform focused on real-time applications.
“Our platform is well-suited for high performance at scale, low latency, and high availability, so that’s what pushed us into looking at graph to really go after this space.”
Aerospike reused its graph database.
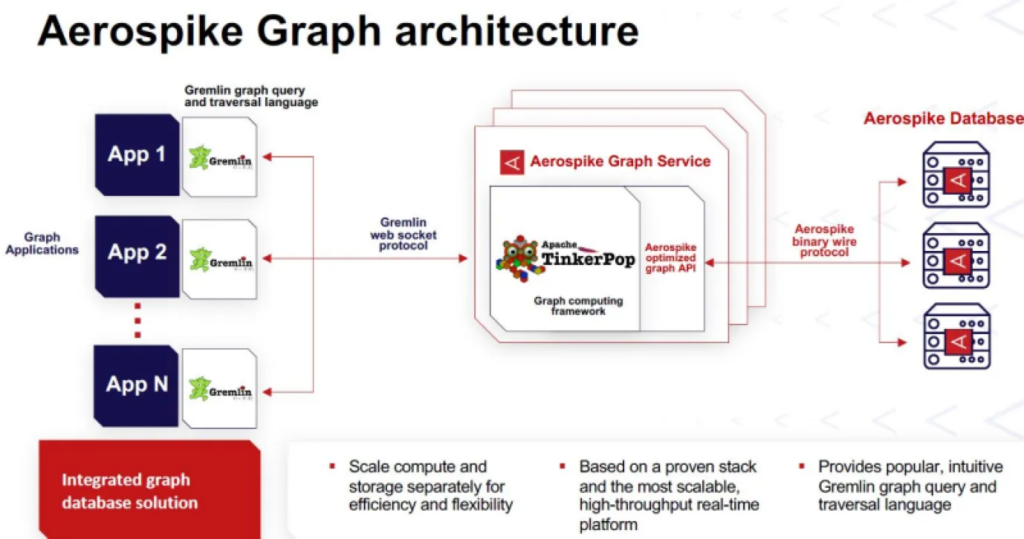
Instead, it used Apache TinkerPop as a foundation. Apache TinkerPop’s Gremlin query language is a graph computing framework.
“When we found Apache TinkerPop, we realized it is a great solution, and we actually work with some of its original authors,” Iyer added.
Aerospike’s graph database is a commercialized TinkerPop. Aerospike Graph separates computing and storage, allowing each to scale independently, Iyer said. On-premises and cloud-based database-as-a-service (DBaaS) models are available.
Aerospike Graph will initially support Apache TinkerPop’s Gremlin query language. Aerospike may support additional graph database query languages, Iyer said. Neo4j’s cypher query language and Oracle’s Property Graph Query Language (PGQL) support graph queries.
Aerospike: AI next?
As Aerospike grows, Iyer prioritizes AI capabilities.
Iyer says enterprises are using the basic Aerospike database technology as a feature store for AI pipelines. In recent months, the industry has also worked to enrich large language model (LLM) data for generative AI using current data sources. Iyer is following vector databases in that space.
Vector databases are under scrutiny, Iyer added. It matches our multi-model strategy perfectly.